Hadoop Operating modes
four main modes of Hadoop operation
- Local runtime mode
- Pseudo-distributed operation mode
- Fully distributed operation mode
- High availability(HA) operating mode
Hadoop Local operation mode
- default mode
- run as a single Java process
- called Local(Standalone) mode
Mode Configuration
- OS: Windows or Linux x64
- The JDK: JDK jdk1.8.0_241
- Hadoop: 3.x
configuration file: hadoop-env.sh
Hadoop pseudo-distributed mode
Overview
- simulate a fully distributed environment
- Hadoop run on a single node
- each Hadoop daemon running on a single server node
- five process
- NameNode
- DataNode
- SecondaryNameNode
- ResourceManager
- NodeManager
HDFS Daemon Process
- HDFS is used to store large amounts of data
- required for the normal operation of the HDFS
- NameNode
- DataNode
- SecondaryNameNode
- run the
start-dfs.shcommand to start the HDFS daemon process to provide external services
Yarn Daemon Process
- the resource management system in Hadoop 3.x
- required
- ResourceManager
- NodeManager
- run
start-yarn.sh
Pattern Configuration(pseudo-distributed mode)
- HDFS Configuration
core-site.xml: NameNode RPC remote communication address. The default port number is8020HDFS-site.xml: set the number of data block copies to 1
- YARN Configuration
mapred-site.xml: set the MapReduce operating framework to YARNyarn-site,xml: set the ResourceManager communication address and aux-services of the NodeManager
- Other Configuration
hadoop-env.sh: set the java environment variables inhadoop.sh
Hadoop HA Running Mode
HDFS HA Architecture
HA architecture solve the problem of NameNode availability by allowing us to have two NameNodes in an active/passive configuration.
Active NameNode
Standby/Passive NameNode
Two main issues in maintaining consistency
- Active and Standby NameNode should always be in sync with each other
- There should be only one active NameNode at a time
Implementation of HA Architecture
- Using Quorum Journal Nodes
- JournalNodes helps the standby and active NameNode keep in sync
- The active NameNode is responsible for updating the EditLogs present in the JournalNodes.
- The StandbyNode reads the changes made to the EditLogs in the JournalNode and applies it to its own namespace in a constant manner.
- Using Shared Storage
- A shared storage device helps standby and active NameNode keep in sync
- The active NameNode logs the record of any modification done in its namespace to an EditLog present in this shared storage.
- The StandbyNode reads the changes made to the EditLogs in this shared storage and applies it to its own namespace.
- The administrator must configure at least one fencing
Hadoop Authority Management
- Hadoop access control is divided into two levels
- system level: ServiceLevel Authorization. It is used to control whether specified services can be accessed.
- scheduler level
Add DataNode
- Add a host name on the master node and copy it on any DataNode node.
- Hadoop has configured the relevant parameters to the newly added DataNode and started it on the new node. Specific steps are as follows:
- Increase hostname
- Copy the hadoop installation file
- Start new node
Reduce DataNode
- Create an exclude file
- Add the node host name to be deleted in the exclude file
Load Balancing
After adding new nodes, if you want to achieve load balancing, you need to use the balance command: bin/start-balancer.sh -threshold 10
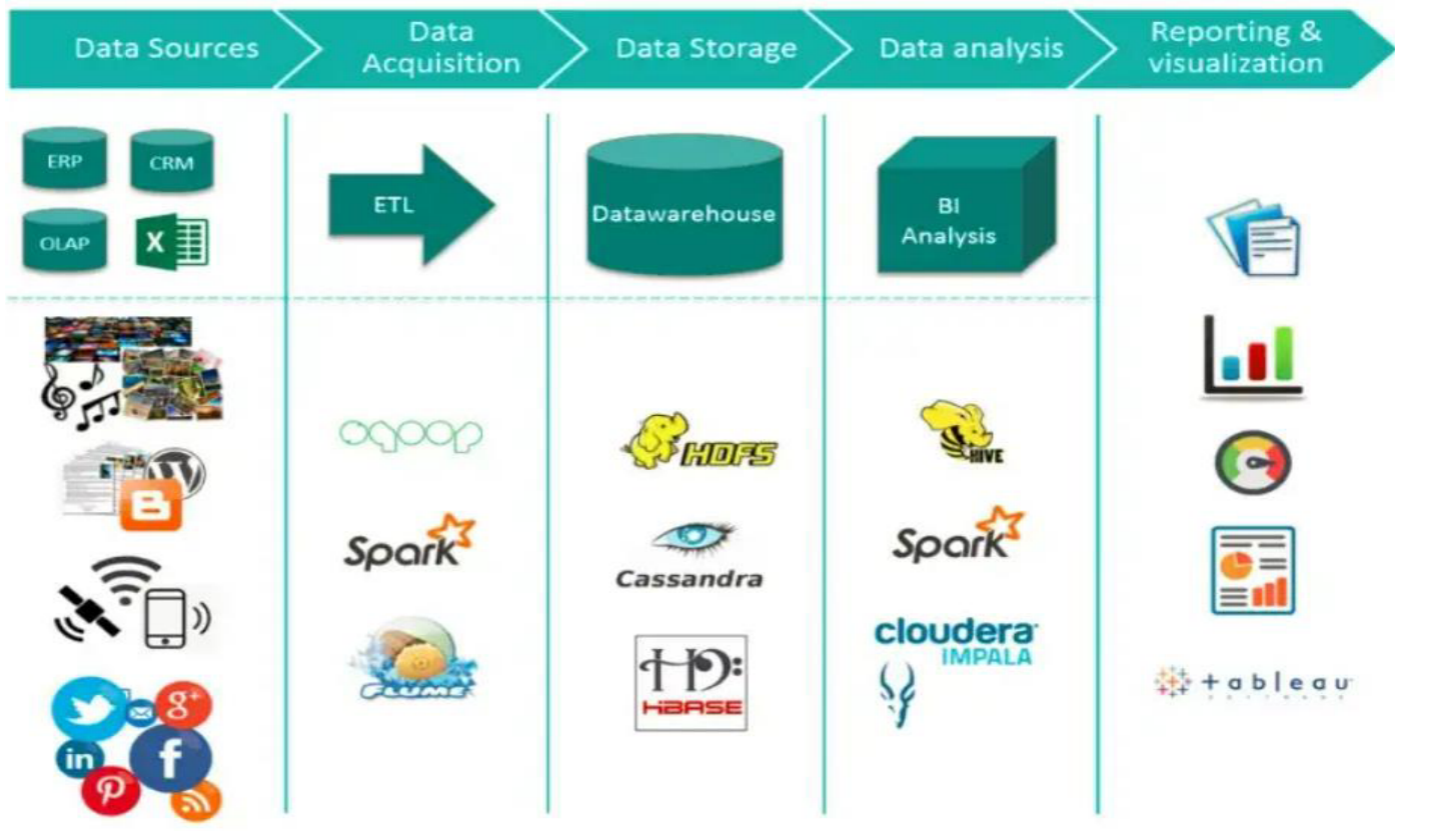
Hadoop and Big data Computing Architecture
Hadoop and Big Data Architecture
- Hadoop Ecosystem is neither a programming language nor a service
- It is a platform or framework which solves big data problems
- Most of the services available in the Hadoop ecosystem are to supplement the main four core components
- HDFS
- YARN
- MapReduce
- Common
Hadoop Real-time Computing Architecture