Hadoop 操作系统模式
Hadoop 四大核心运行模式
- 本地运行模式
- 伪分布式运行模式
- 完全分布式运行模式
- 高可用性(HA)运行模式
Hadoop 本地运行模式
- 默认运行模式
- 以单个 Java 进程运行
- 又称作本地(独立)模式
模式配置要求
- 操作系统: Windows 或 Linux x64
- JDK 版本: JDK jdk1.8.0_241
- Hadoop 版本: 3.x
核心配置文件: hadoop-env.sh
Hadoop 伪分布式模式
模式概述
- 模拟完全分布式环境
- 单节点运行 Hadoop
- 所有 Hadoop 守护进程运行于同一服务器节点
- 包含五大核心进程
- 名称节点(NameNode)
- 数据节点(DataNode)
- 第二名称节点(SecondaryNameNode)
- 资源管理器(ResourceManager)
- 节点管理器(NodeManager)
HDFS 守护进程
- HDFS 用于存储海量数据
- 正常运行所需进程
- NameNode
- DataNode
- SecondaryNameNode
- 执行
start-dfs.sh命令启动 HDFS 守护进程对外提供服务
Yarn 守护进程
- Hadoop 3.x 资源管理系统
- 核心进程
- ResourceManager
- NodeManager
- 执行
start-yarn.sh启动服务
伪分布式模式配置
- HDFS 配置
core-site.xml: 配置 NameNode RPC 远程通信地址,默认端口号8020hdfs-site.xml: 设置数据块副本数为 1
- YARN 配置
mapred-site.xml: 指定 MapReduce 运行框架为 YARNyarn-site.xml: 配置 ResourceManager 通信地址及 NodeManager 辅助服务
- 其他配置
hadoop-env.sh: 设置 hadoop.sh 中的 Java 环境变量
Hadoop 高可用性运行模式
HDFS 高可用架构
- 通过主备双 NameNode 机制提升可用性
- 活跃 NameNode(Active)
- 备用 NameNode(Standby/Passive)
- 需解决两大核心问题
- 主备 NameNode 状态实时同步
- 同一时刻仅允许一个活跃节点
HA 架构实现方案
- 仲裁日志节点方案
- 通过 JournalNodes 集群保持主备同步
- 活跃 NameNode 将 EditLog 更新至 JournalNodes
- 备用节点持续读取 JournalNodes 的 EditLog 变更并应用
- 共享存储方案
- 通过共享存储设备保持主备同步
- 活跃 NameNode 将命名空间修改记录至共享存储的 EditLog
- 备用节点读取共享存储的 EditLog 变更并应用
- 管理员必须配置至少一种隔离机制(fencing)
Hadoop 权限管理
- 两级访问控制体系
- 系统级: 服务级别授权(ServiceLevel Authorization),控制指定服务是否可访问
- 调度器级
动态扩容 DataNode
- 在主节点增加主机名配置,并同步至所有 DataNode 节点
- Hadoop 已预制新 DataNode 配置参数,扩容步骤如下:
- 新增主机名至 hosts 文件
- 分发 hadoop 安装文件至新节点
- 启动新节点服务
动态缩容 DataNode
- 创建 exclude 排除文件
- 将待下线节点主机名加入排除文件
负载均衡
节点扩容后如需实现负载均衡,需执行平衡命令:
| |
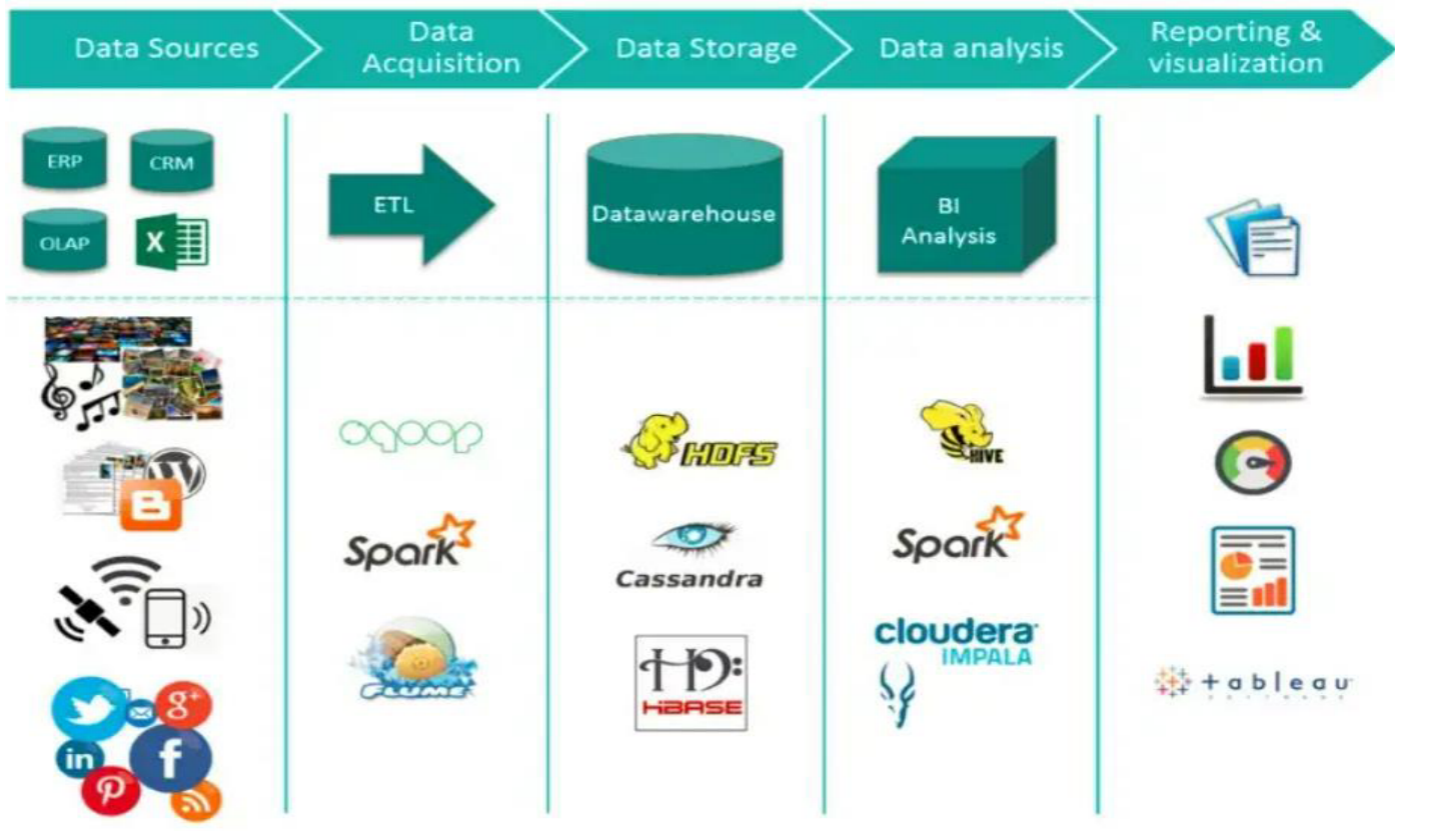
Hadoop 与大数据计算架构
Hadoop 大数据生态定位
- Hadoop 生态既非编程语言亦非服务
- 是解决大数据问题的平台框架
- 生态中多数服务围绕四大核心组件扩展
- 分布式存储 HDFS
- 资源调度 YARN
- 计算框架 MapReduce
- 公共组件库 Common
Hadoop 实时计算架构