
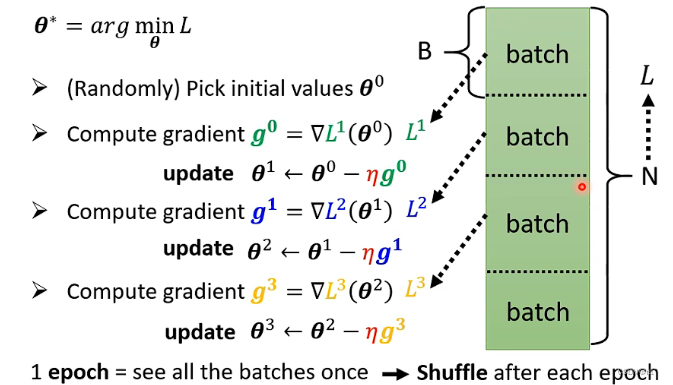
批次(batch)与动量(momentum)
批次
- 小批量梯度下降(Mini-batch Gradient Descent)
- 在训练模型时,不直接使用全部数据计算梯度,而是将数据划分为多个小批量(batch),每次用一个batch的数据计算损失(Loss)和梯度,并更新模型参数。
- 相比全量梯度下降(计算所有数据),减少内存占用和计算量,同时比随机梯度下降(单个样本)更稳定。
- Batch(批次)与Epoch(轮次)
- Batch:将训练数据分成若干固定大小的子集(如B个样本),每个子集称为一个batch。
- Epoch:完整遍历一次全部训练数据的过程(即所有batch被计算一遍)。每个epoch结束后,模型完成一次完整训练。
- 关系:1个epoch = 所有batch依次计算并更新参数。
- 参数更新机制
- 逐batch更新:每个batch计算一次Loss和梯度后,立即更新参数(而非累积所有batch的梯度再更新)。
- 优点:加快收敛速度,避免全量数据计算的资源瓶颈。
- Shuffle
- 作用:在每个epoch开始前,随机打乱训练数据的顺序,再划分batch。
- 目的:防止模型因数据顺序产生偏差(如学习到数据排列规律),增强泛化能力。
- 结果:每个epoch的batch组成不同,提升训练随机性。
为什么训练时需要用batch?
参数更新更快,每看一笔资料即会更新一次参数

Small batch vs Large batch
- 没有平行运算时,Small Batch比Large Batch更有效
- 有平行运算时,Small Batch与Large Batch运算时间没有太大差距,除非大的超出一定界限
- 在一个epoch时间内,Large Batch比Small Batch更快,Large Batch更有效率
- Small Batch比较陡,Large Batch比较稳定
- 比较noisy的batch size比比较stable 的batch size在训练和测试时占有优势
自动调整学习率
随着参数的更新,loss值逐渐变小并保持在一定值不再下降
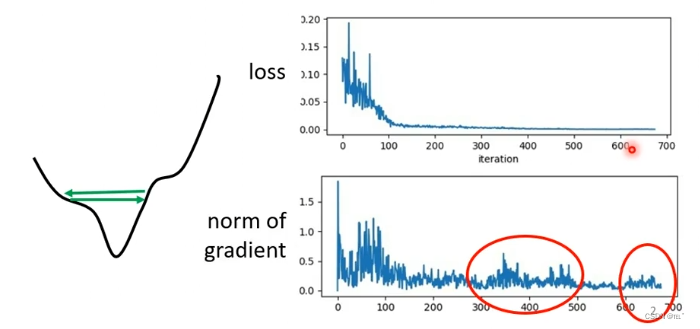
将gradient decent做的更好的方法是设置每一个参数的学习效率
- 如果在某一个方向上,gradient值很小(比较平稳),那么应该把学习效率调高;
- 如果在某一个方向上,gradient值很大(比较陡峭),那么应该把学习效率调低。