
Critical Point情况
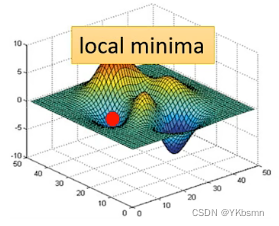
- 局部最小值(local minima)。如果是**卡在local minima,那可能就没有路可以走了,**因为四周都比较高,你现在所在的位置已经是最低的点,loss最低的点了,往四周走 loss都会比较高,你会不知道怎么走到其他地方去。
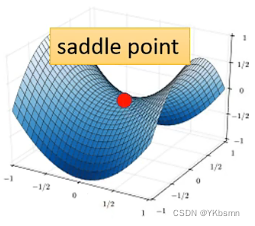
- 鞍点(saddle point)。(如图可看出,左右是比红点高,前后比红点低,红点既不是local minima,也不是local maxima的地方)如果是卡在saddle point,saddle point旁边还是有其他路可以让你的loss更低的,你只要逃离saddle point,你就有可能让你的loss更低。
确定Critical Point类型
使用泰勒级数近似 $$ L(\theta)\approx L(\theta ^{’})+L(\theta - \theta^{’})g+\frac{1}{2}(\theta-\theta^{’})^{T}H(\theta-\theta ^{’}) $$ 计算Hessian矩阵的特征值
- 正定(所有特征值 > 0)→ 局部极小值
- 负定(所有特征值 < 0)→ 局部极大值
- 不定(特征值有正有负)→ 鞍点
- 半正定/半负定(存在零特征值)→ 需更高阶分析(如退化临界点)
具体例子
- 案例1:正定Hessian → 局部极小值
$$ H=\begin{bmatrix} 2 & 1 \ 1 & 2 \end{bmatrix} $$
- 特征值:3和1(均 > 0)→ 正定
- 结论:局部极小值
- 案例2:负定Hessian → 局部极大值
$$ H=\begin{bmatrix} -2 & 0 \ 0 & -2 \end{bmatrix} $$
- 特征值:-2 和 -2(均 < 0)→ 负定
- 结论:局部极大值。
- 案例3:不定Hessian → 鞍点
$$ H = \begin{bmatrix} 2 & 0 \ 0 & -2 \end{bmatrix} $$
- 特征值:2 和 -2(有正有负)→ 不定
- 结论:鞍点
逃离Saddle Point
利用Hessian矩阵逃离鞍点(Saddle Point)
核心思想:通过Hessian矩阵的负特征值对应的特征向量方向更新参数,使优化方向逃离鞍点。
具体步骤
- 1. 检测鞍点
- 计算梯度$\nabla f$,若$||\nabla f|| \approx 0$,则可能为临界点
- 计算Hessian矩阵$H$,并分析其特征值
- 若存在负特征值,则为鞍点。
- 2. 找到负曲率方向
- 对Hessian矩阵进行特征分解,找到最小特征值$\lambda_{\min} < 0$及其对应的特征向量$v_{\min}$。
- 3. 沿负曲率方向更新参数
- 选择步长$\eta$(通常与学习率相关),沿$v_{min}$方向更新参数:$\theta_{new}=\theta_{old}+\eta v_{min}$
- **验证方向:**通过计算$\theta_{new}=\theta_{old}+\eta v_{min}$和$\theta_{new}=\theta_{old}-\eta v_{min}$,选择使函数值下降的方向
- 4. 迭代直至逃离
- 重复步骤1-3,直到梯度不再接近0或Hessian矩阵变为正定(局部最小值)
利用momentum逃离鞍点
动量法的基本原理
动量法(Momentum)是梯度下降的改进版本,通过积累历史梯度方向加速收敛并抑制振荡。其更新公式为: $$ v_t = \beta v_{t-1} + (1-\beta) \nabla f(\theta_t) $$
$$ \theta{t+1} = \theta_t - \eta v_t $$
- 动量系数:$$\beta \in [0, 1)$$,通常取0.9或0.99。
- 核心思想:梯度方向被赋予“惯性”,在平坦区域(如鞍点)积累动量,帮助逃离。
动量如何帮助逃离鞍点?
鞍点的特征:梯度$$\nabla f \approx 0$$,但Hessian矩阵存在负曲率方向。
- 梯度下降的缺陷:在鞍点附近,梯度接近零,参数更新停滞。
- 动量的优势:
- 历史梯度累积:即使当前梯度为零,动量项$$v_t$$仍可能保留之前方向的惯性。
- 噪声放大:随机梯度(如SGD的小批量噪声)会被动量放大,打破对称性。
- 负曲率方向探索:动量推动参数沿历史梯度方向移动,可能进入负曲率区域。
动量逃离鞍点的数学解释
假设在鞍点附近,梯度方向存在随机扰动$$\epsilon_t$$(如小批量噪声): $$ \nabla f(\theta_t) = \epsilon_t \quad (\mathbb{E}[\epsilon_t] = 0, \text{Var}(\epsilon_t) = \sigma^2) $$ 动量更新公式变为: $$ v_t = \beta v_{t-1} + (1-\beta) \epsilon_t $$
- 动量积累:经过$$k$$步后,动量近似为: $$ v_t \approx (1-\beta) \sum_{i=0}^{k} \beta^{k-i} \epsilon_i $$
- 逃离机制:噪声的加权和可能指向负曲率方向,使参数突破鞍点。
具体步骤与算法
步骤1:初始化动量
设置初始动量$$v_0 = 0$$,选择动量系数$\beta$和学习率$\eta$。
步骤2:迭代更新
对每次迭代$t$:
- 计算当前梯度$\nabla f(\theta_t)$(可含噪声,如SGD)。
- 更新动量: $$ v_t = \beta v_{t-1} + (1-\beta) \nabla f(\theta_t) $$
- 更新参数: $$ \theta_{t+1} = \theta_t - \eta v_t $$
步骤3:逃离鞍点的动态
- 鞍点附近:梯度$\nabla f \approx 0$,但动量$v_t$可能因历史梯度或噪声不为零。
- 持续更新:动量推动参数离开平坦区域,进入梯度较大的区域。
实验案例:动量法逃离二元鞍点
目标函数
$$ f(x, y) = x^2 - y^2 $$
- 鞍点:$(0, 0)$,Hessian矩阵特征值为$2$和$-2$。
参数设置
- 初始点:$(0.1, 0.1)$,学习率$\eta = 0.1$,动量系数$\beta = 0.9$。
迭代过程
- 第1步:梯度$\nabla f = (0.2, -0.2)$,动量$v_1 = 0.1 \times (0.2, -0.2)$,更新后点$(0.08, 0.12)$。
- 第2步:梯度$\nabla f = (0.16, -0.24)$,动量$v_2 = 0.9v_1 + 0.1 \times (0.16, -0.24)$,更新后点$(0.064, 0.144)$。
- 持续迭代:动量在$y$方向逐渐积累,推动逃离鞍点区域。
动量法的理论支持
- 收敛性证明:在凸函数中,动量法可加速收敛(Nesterov加速)。
- 逃离鞍点能力:
- 随机梯度(SGD):噪声+动量可概率性逃离鞍点(Ge et al., 2015)。
- 确定性梯度:动量法需依赖Hessian的负曲率方向隐含在历史梯度中。
与其他方法的对比
| 方法 | 逃离鞍点机制 | 计算成本 | 适用场景 |
|---|---|---|---|
| 动量法 | 历史梯度惯性 + 噪声放大 | 低(一阶) | 高维、随机优化(如深度学习) |
| Hessian矩阵法 | 显式利用负曲率方向 | 高(二阶) | 低维、确定性优化 |
| SGD + 扰动 | 纯随机噪声探索 | 低(一阶) | 大规模非凸优化 |
实际应用技巧
- 动量系数选择:$\beta$越大,惯性越强,但可能“冲过头”。常用$\beta=0.9$。
- 与自适应方法结合:如Adam(动量+RMSProp),平衡方向与步长。
- 学习率调整:在鞍点附近可短暂增大学习率以加速逃离。
优缺点分析
| 优点 | 缺点 |
|---|---|
| 低计算成本,适合高维问题。 | 无显式二阶信息,依赖噪声或历史梯度。 |
| 天然抗噪声,适合随机优化。 | 对某些鞍点(如高阶退化点)可能失效。 |
| 易与其他优化器结合(如Adam)。 | 需调参($\beta$, $\eta$)。 |