
原文链接
知识清单
Abstract
- 小样本学习方法(few-shot learning):让模型仅通过极少量样本(如1-5个样本,称为1-shot或5-shot)快速学习新任务
- 元学习(meta-learning):通过大量相似任务(如分类不同模型)训练模型
- 例如:训练时让模型学习“如何区分5种类别的鸟类”,测试时快速适应“区分5种新鸟类”。
- 跨领域小样本学习(cross-domain few-shot):基础数据集与目标数据集来自不同领域(如自然图像→医学影像),且目标数据极少或无标签
- STARTUP:解决跨领域小样本学习中目标数据无标签的问题
- 自训练(self-training):用预训练教师模型对无标签目标数据生成伪标签(即软标签),再结合少量标注数据训练学生模型
- 固定教师
- 软标签(soft labels):概率分布形式的标签(如[0.7, 0.3]表示“70%概率是类别A”),而非硬标签(如[1, 0])
- 弱增强(weakly-augmented):对输入数据施加轻微变换的预处理操作,比强增强更温和
Introduction
指数移动平均(EMA):通过加权平均更新参数,赋予近期参数更高的权重,同时保留历史参数的衰减影响。
- 教师网络的参数$\theta_t$由学生网络参数$\theta_s$通过EMA更新。其中$\beta$是衰减率
$$ \theta_t \leftarrow \beta \cdot \theta_t + (1-\beta)\cdot \theta_s $$
蒸馏(Distillation):知识蒸馏是一种将“教师模型”的知识迁移到“学生模型”的技术,通常通过让学生模仿教师的输出来实现。核心思想是让学生学习教师的软标签(概率分布),而不仅是真实标签的硬标签。
- 教师生成软标签:输入数据经教师模型前向传播,输出概率分布(如分类任务的类别概率)
- 学生匹配软标签:学生模型对相同(或增强后的)数据输出概率,并通过损失函数(如 KL 散度)逼近教师的输出。
支持集(Support Set):一小批带有标签的样本,用来“教”模型快速认识新任务中的类别。
查询集(Query Set):一批需要分类的样本,用来测试模型是否真正学会了新类别。
注意:支持集和查询集、训练集和测试集是有不同的
- 训练集/测试集的目的是训练一个模型解决单一固定任务
- 支持集/测试集让模型快速适应新任务
- 训练集 vs 支持集:如果只用支持集(如每类1张图)训练传统模型,模型会严重过拟合(只会背答案,无法泛化)。支持集必须配合元学习框架,让模型提前掌握“快速学习能力”。
- 测试集 vs 查询集:测试集是静态的,任务固定;查询集是动态的,每次任务不同(如今天分类鸟类,明天分类岩石)。查询集的评估目标是“模型能否快速适应新任务”,而非“是否精通某一任务”。
Related Work
- 生成式方法:通过生成新样本来扩充数据
- 自己画一些假狗的照片(生成数据),结合真实照片一起训练
- 比如用尺子量新照片和样本照片的"鼻子长度"“耳朵形状"等特征,越像狗分越高
- 自己画一些假狗的照片(生成数据),结合真实照片一起训练
- 基于度量的方法:核心是学习样本间的相似度计算方式、
- Matching Networks:把照片变成数学向量,计算相似度
- Prototypical Networks:先计算所有样本的平均特征(比如哈士奇平均有蓝眼睛、竖耳朵),新照片和这个平均值对比
- Relation Networks:让AI自己发明一套「相似度计算公式」,而不是用现成的余弦相似度
- 基于自适应的方法:通过参数调整快速适应新任务
- MAML:提前把模型参数训练得像橡皮泥一样,遇到新任务只需微调几步
- 比如先学会识别动物轮廓,遇到新动物时快速调整细节(斑马条纹/长颈鹿脖子)
- MAML:提前把模型参数训练得像橡皮泥一样,遇到新任务只需微调几步
- 元学习(Meta-learning):“学会学习”的范式,通过多个任务训练模型获取可迁移的知识
- 先让AI玩100个「用5张图认新东西」的小游戏(每个游戏认不同动物)
- AI在这些游戏中总结出经验:比耳朵形状比颜色更重要,先看轮廓再看细节
- 遇到新游戏(比如用5张企鹅照片认企鹅),就能快速应用这些经验
- 自训练(Self-training):一种半监督学习方法,其核心思想是通过模型自身的预测结果(伪标签)逐步扩充训练数据
- 基本流程
- 初始训练:使用少量有标签数据训练基础模型(Teacher Model)
- 伪标签生成:用该模型预测无标签数据的类别,筛选高置信度预测结果作为伪标签
- 数据扩充:将伪标签数据与原始有标签数据合并,重新训练模型(Student Model)
- 迭代优化:重复步骤2-3,直至模型收敛或达到终止条件
- 通俗解释:假设你是一个学生
- 第一步:老师先教你10道数学题(有标签数据),你学会了基本解法
- 第二步:老师布置100道新题(无标签数据),你先用学会的方法做完,并挑出自己最有把握的50道题(高置信度伪标签)
- 第三步:把这50道自认为正确的题当作「参考答案」,结合原来的10道题重新复习
- 第四步:重复做题→选答案→复习的过程,直到你觉得所有题都会了
- 注意风险:如果前几步自己做错了还当成正确答案,后面会越错越离谱(错误累积)。所以老师通常会要求:只相信95分以上的答案(置信度阈值),或者让多个同学互相对答案(多模型协同)
- 基本流程
- 半监督学习(Semi-supervised Learning):用少量带答案(标签)和大量不带答案的数据(无标签)一起训练模型
- FixMatch:用自信的猜测教自己
- STARTUP(Self-Training Adaptation Using Pseudo-labels):通过伪标签和自监督对比学习,,利用目标领域的未标注数据提升模型在跨域任务中的性能。
- 核心问题设定:
- 基础域(Source Domain):有大量标注数据(如自然图像)
- 目标域(Target Domain):仅有极少量标注数据(如医学图像),但可能有大量未标注数据。
- 目标:让模型从基础域迁移到目标域,仅用少量目标域标注样本实现高精度分类。
- 方法流程
- 预训练模型:在基础域上训练一个分类模型(如ResNet),作为固定(Frozen)的预训练模型。
- 生成伪标签:使用预训练模型对目标域的未标注数据生成伪标签(即预测结果作为“软标签”)
- 联合训练:结合基础域的标注数据(真实标签)和目标域的伪标签数据,重新训练模型。
- 自监督对比学习:在未标注数据上加入对比损失(如SimCLR),学习对数据增强鲁棒的特征表示。
- 大白话:先蒙答案,蒙完再改,改的时候还要自我检查
- 核心问题设定:
品,细品
Abstract
- 现有工作:依赖于在与目标数据集同域的大型基础数据集上进行网络元学习
- 缺陷:在基础域和目标域存在显著差异的跨域小样本学习效果不行
- 本文提出:使用动态蒸馏,有效利用新/基础数据集的未标记图像
- 通过教师网络对未标记图像的弱增强版本生成预测
- 通过学生网络对同一图像的强增强版本进行预测
- 通过一致性正则化约束两者匹配
- 教师网络的参数通过学生网络参数的指数移动平均动态更新
Introduction
典型小样本学习、跨领域小样本学习、本文提出的新设定的区别
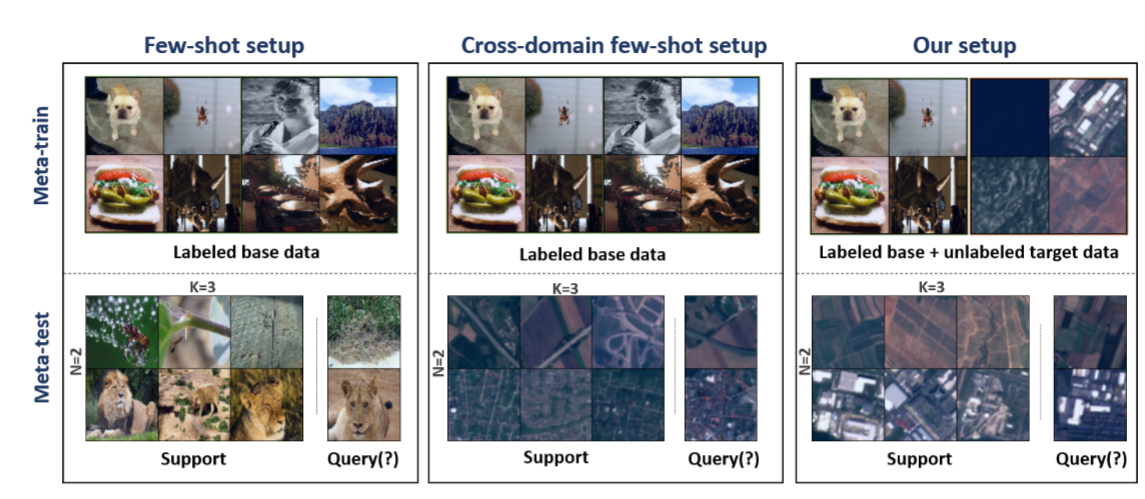
- 典型小样本学习(左)
- 基础数据集和目标数据集来自同一领域
- 类别互不相交
- 跨领域小样本学习(中)
- 基础数据集与目标数据存在领域差异
- 本文提出的设定(右)
- 在元训练阶段引入无标签目标数据
通俗易懂的解释:
- 典型小样本学习(左):你是一个只会画“猫和狗”的画家,现在要快速学会画“鸟和鱼”。
- 基础训练:你之前画过大量不同品种的猫和狗(同一领域:动物)
- 小样本任务:客户给你看1张鸟的照片和1张鱼的照片(支持集),要求你画出这两种动物的其他姿势(查询集)
- 关键点
- 你学的(猫狗)和要画的(鸟鱼)都是动物,只是品种不同(同一领域,类别不相交)
- 你靠之前的动物绘画经验(如毛发、眼睛的画法),快速模仿鸟和鱼的特征
- 类比总结
- 领域相同:全是动物
- 挑战:用旧知识(画猫狗)解决同类新问题(画鸟鱼)
- 跨领域小样本学习(中):你是一个画“自然风景”的画家,现在要快速学会画“抽象几何图形”
- 基础训练:你之前画过大量山川、河流、树木(自然领域)
- 小样本任务:客户给你看1个三角形和1个圆形(支持集),要求你画出其他几何图形(如六边形)
- 关键点
- 自然风景(曲线、光影)和几何图形(直线、对称)属于完全不同的领域
- 你只能用画风景的经验(如颜色搭配)去“硬猜”如何画几何图形,效果可能很差
- 类比总结
- 领域不同:自然风景 vs. 几何图形
- 挑战:旧经验(自然)和新任务(几何)毫无关联,从头适应难如登天
- 本文提出的新设定:你是一个画“自然风景”的画家,但客户提前给了你一堆未标注的几何图形草稿,现在要快速学会画“抽象几何图形”
- 基础训练
- 你画过大量自然风景(带标签的源数据)
- 还看过很多未标注的几何图形草稿(无标签目标数据),虽然不知道它们具体是什么,但熟悉了直线、对称等特征。
- 小样本任务:客户给你看1个三角形和1个圆形(支持集),要求你画出其他几何图形。
- 关键点
- 未标注的几何草稿让你提前适应了“几何领域”的风格(如直线比曲线多)。
- 结合自然风景的绘画技巧(如色彩搭配)和几何领域的特征,你能更快画出客户想要的图形。
- 类比总结
- 领域不同:自然风景(源) vs. 几何图形(目标)。
- 秘密武器:提前看过未标注的几何草稿(无标签目标数据),相当于“预习”了新领域的规则。
- 基础训练
Related Work
Few-shot classification: 少样本分类可分为三大类:生成式、基于度量、基于适应。早期少样本学习工作基于元学习
Self-training: 自训练通过训练学生模型来模仿教师模型的预测
Semi-supervised Learning:
- 核心思想:同时利用少量有标签数据和大量无标签数据进行训练
- FixMatch方法核心逻辑
- 弱增强生成伪标签:对无标签图像做弱增强(如平移、旋转),用模型预测其伪标签。
- 强增强训练一致性:若伪标签置信度高,则对同一图像做强增强(如颜色失真、模糊),并让模型预测与伪标签一致。
- 作者改进方法
- 一致性正则化:强制模型对同一数据的不同增强版本(如弱增强和强增强)输出一致。与FixMatch类似,但不假设无标签数据与有标签数据同领域。
- 均值教师网络:用教师模型(Teacher Network)生成伪标签,学生模型(Student Network)学习。教师模型是学生模型的指数移动平均(EMA),稳定性更高,伪标签噪声更小。
Cross-domain few-shot learning
- 现有最先进方法在跨域少样本学习上难以达到理想准确率
- 现有方法:STARTUP
- 方法:用预训练模型为未标记的目标域数据生成伪标签,结合基础域标注数据和目标域伪标签训练模型。
- 局限:伪标签依赖固定预训练模型,若模型不适应目标领域,错误会累积(如用自然图像预训练的模型直接标注医学影像)。需要额外设计自监督对比损失(如SimCLR),增加计算复杂度。
- 本文方法:动态蒸馏(Dynamic Distillation)
- 监督学习:使用标记的基础数据集优化监督交叉熵损失。
- 动态蒸馏
- 对目标图像的弱增强版本,用教师网络生成预测
- 对同一图像的强增强版本,由学生网络生成预测
- 通过蒸馏损失约束两者预测分布一致
- 教师预测应用温度锐化以鼓励学生输出低熵预测
- 参数更新:学生网络通过监督损失和蒸馏损失联合优化,教师网络参数采用学生网络的指数移动平均更新。
- 少样本评估:仅需在少样本支撑集上学习新分类器头,直接对查询集进行评估。
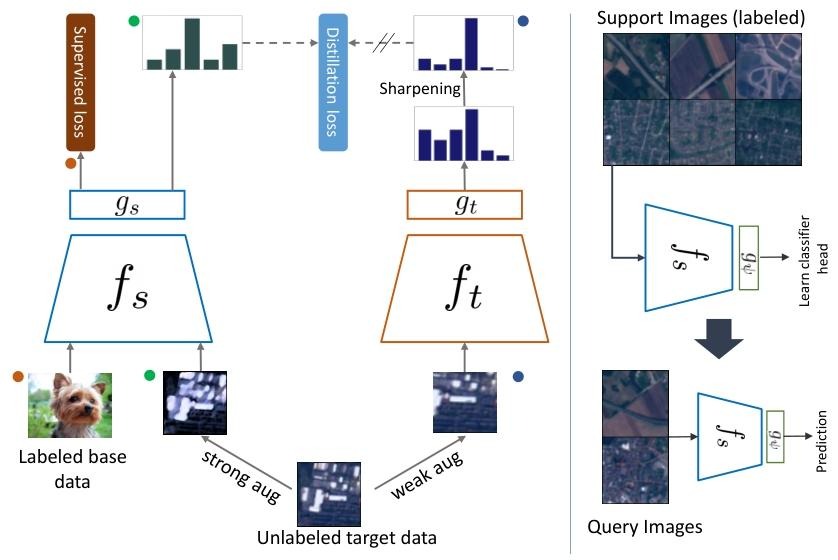
Methodology
Proposed Method
Encoder:通过知识蒸馏方法,在源数据集和目标数据集上联合训练基础编码器。将嵌入网络表示为$f_s$,它将输入图像$x$编码为一个$d$维向量$f_s(x)$。我们在$f_s$上添加一个分类头$g_s$,用于从嵌入向量中预测$n_c$个逻辑值(logits),其中$n_c$是基数据集(base dataset)的类别总数。由于基数据集中的样本标签已知,我们计算监督交叉熵损失: $$ l_{CE}(y,p)=H(y,p)\ p=Softmax(g_s(f_s(x))) H(a,b)=-alog b $$
- 核心目标:通过知识蒸馏(类似“老师教学生”),让编码器同时学习源数据集(如动物图片)和目标数据集(如医疗X光片)的特征,提升跨域任务的泛化能力。
- 模型结构
- 编码器$f_s$:将输入图像(如一张x光片)转换为一个向量,这个向量代表图像的特征(如形状、纹理)
- 分类器头$g_s$:接在编码器后面,将特征向量映射到类别概率
- 监督损失
- 输入:源数据集(带标签)的图片
- 计算步骤:
- 编码器提取特征 $\rightarrow f_s(x)$
- 分类器预测类别概率 $\rightarrow p = Softmax(g_s(f_s(x)))$
- 用交叉熵损失$l_{CE}$衡量预测概率$p$和真实标签$y$的差距
- 通俗解释:如果真实标签是“肺炎”,但模型预测概率为0.1,损失会很大;如果预测概率是0.9,损失就小。这个过程迫使编码器和分类器学习源数据集的分类能力。
Dynamic distillation:
- 核心思想
- 教师-学生模式:教师网络生成“参考答案”(伪标签),学生网络通过模仿教师来学习
- 动态更新:教师网络不是固定的,而是随着学生网络的训练逐步更新,类似“老师跟着学生一起进步”。
- 关键步骤
- 数据增强:迫使模型对不同增强版本预测一致,提升鲁棒性
- 伪标签生成:
- 教师网络处理弱增强图像$x_i^w$,生成软目标$p_i^w$(概率分布,而非硬标签)
- 学生网络处理强增强图像$x_i^s$,生成预测$p_i^s$
- 损失计算
- 监督损失$l_{CE}$:在源数据(带标签)上计算交叉熵损失
- 蒸馏损失$l_U$:迫使学生网络的预测$p_i^s$与教师网络的伪标签$p_i^w$一致
- 总损失是两者的加权和($\lambda$控制未标记数据的重要性)
- 教师网络更新
- 教师网络的权重是学生网络权重的历史平均(动量更新)
- 动态更新使得教师网络更稳定,避免伪标签噪声过大。
- 核心思想
Experiments
Experimental Setup
数据集
- 基数据集(Base Dataset)
- miniImageNet:从
ImageNet中选取的100个类别,每个类别含600张图像(总计60,000张),类别覆盖通用物体(如动物、日常用品),用于监督预训练。 - tieredImageNet:更大的基数据集,包含608个类别(34个超类),分为训练(351类)、验证(97类)、测试(160类),用于验证模型对大规模数据的泛化性。
- miniImageNet:从
- 新领域数据集(Novel Dataset)
- CropDisease:农业植物病害图像,类别与miniImageNet的语义差异显著(领域差异大)。
- EuroSAT:遥感卫星图像(土地利用分类),与自然图像分布不同(低分辨率、多光谱特征)。
- ISIC:皮肤病医学影像(皮肤镜图像),模态差异明显(纹理、颜色分布独特)。
- ChestX:胸部X光影像(肺炎分类),灰度图像且解剖结构复杂。
- 选择依据:按与miniImageNet的领域差异递增排序(CropDisease差异最小,ChestX差异最大),用于测试跨域小样本泛化性。
- 数据划分协议
- 无标签集$D_U$:从每个新数据集中随机抽取20%样本(例如,CropDisease若含1,000张,则取200张作为$D_U$)
- 评估集:剩余80%样本用于
5-way K-shot1分类任务(支持集采样K张/类,查询集评估)。
- 基数据集(Base Dataset)
小样本评估:在支持集上训练逻辑回归分类器,在查询集测试性能
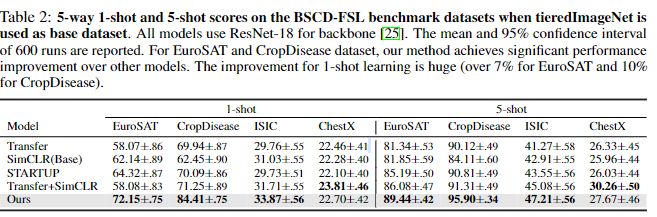
实验1:BSCD-FSL基准测试duibi

- 模型对比:
- 传统元学习(MetaOpt、MAML、ProtoNet)
- 自监督学习(SimCLR)
- 混合方法(Transfer+SimCLR)
- 最新跨域方法(STARTUP)
- 训练设置
- 基础数据集:miniImageNet(80 类)
- 目标数据集:未标记数据(20% 目标集)
- 主干网络:ResNet-10(miniImageNet)
- 评估指标:5 分类 1-shot/5-shot 准确率(600 次运行的均值 ±95% 置信区间)
- 优点
- Ours 在所有数据集上均超越 STARTUP(平均提升 5.5%~8.8%)
- 动态教师网络生成的伪标签随训练优化,优于固定教师(STARTUP)
- 模型对比:
实验2:tiredImageNet基础数据实验
- 目的:验证方法在大规模基础数据集上的泛化性
- 数据集:tieredImageNet(608 类,划分为 34 个超级类别)
- 模型对比:
- 基于 miniImageNet 的基准
- 基于 tieredImageNet 的基线
- 训练设置
- 更大主干网络:ResNet-18
- 元训练策略:MAML 框架
- 评估指标:5 分类 1-shot/5-shot 准确率
- 关键发现:
- 使用 tieredImageNet 预训练未显著提升性能(对比 miniImageNet)
- 验证跨域少样本学习中数据质量>数据量的假设
实验3:相似域少样本性能

- 目的:验证方法在同域 / 相似域的有效性
- 数据集
- miniImageNet(同域)
- tieredImageNet(相似域)
- 训练设置:
- 未标记数据来自目标域测试集的 20%
- 主干网络:ResNet-10(miniImageNet)、ResNet-18(tieredImageNet)
- 对比对象:
- Transfer(仅监督训练)
- STARTUP(同域无效)
- 关键发现:
- Ours 在同域任务中仍优于 STARTUP(tieredImageNet 1-shot 提升 7.7%)
- 动态蒸馏对域差异不敏感,兼具跨域和同域适应性
实验4:动态蒸馏效果分析
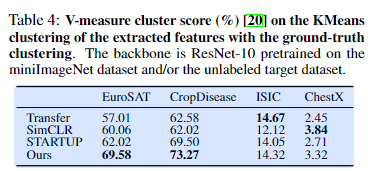

- 目的:揭示动态蒸馏如何优化特征表示
- 量化分析(表 4):
- 方法:K 均值聚类 + V-measure 评分
- 指标:真实标签与聚类结果的一致性(V-score)
- 可视化分析(图 3):
- 方法:t-SNE 降维展示特征分布
- 对比:Transfer 基准 vs Ours
- 关键发现
- 聚类质量:Ours 在 EuroSAT(85.2%)和 CropDisease(91.3%)上 V-score 最高
- 特征分离:可视化显示 Ours 生成的嵌入具有更好的类间区分性
- 机制验证:蒸馏损失隐式促进特征聚类,无需显式对比学习
5-way指在小样本学习任务中,对5个类别进行分类。K-shot指每个分类提供k个带标签的样本作为训练支持集 ↩︎